File:An-striker01-rhel9-m3-peering-08.png
No higher resolution available.
An-striker01-rhel9-m3-peering-08.png (706 × 487 pixels, file size: 239 KB, MIME type: image/png)
Summary
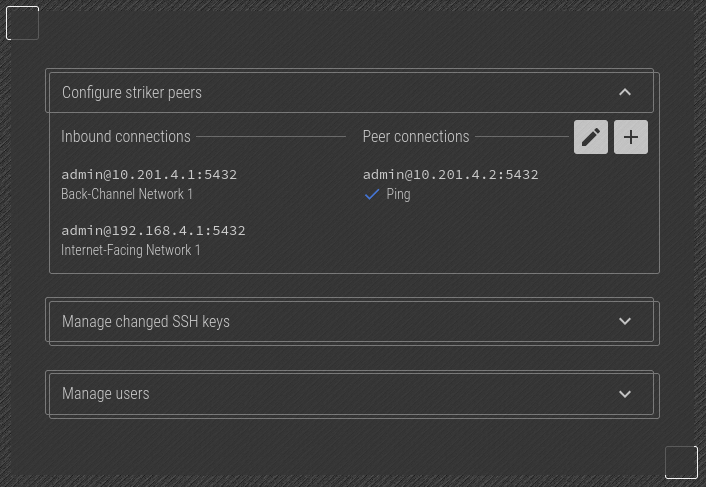
The peer Striker is now displayed.
File history
Click on a date/time to view the file as it appeared at that time.
| Date/Time | Thumbnail | Dimensions | User | Comment | |
|---|---|---|---|---|---|
| current | 00:43, 18 July 2024 | | 706 × 487 (239 KB) | Digimer (talk | contribs) | The peer Striker is now displayed. |
You cannot overwrite this file.
File usage
The following 2 pages use this file:
{kind=link}